Overview
The Latent AI Efficient Inference Platform (LEIP) is a modular, fully-integrated workflow for AI scientists and embedded software engineers. The LEIP software development kit (SDK) enables developers to train, quantize and deploy efficient deep neural networks.
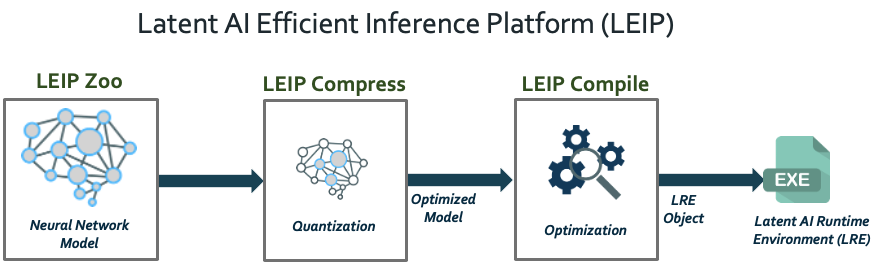
The LEIP SDK includes the following service modules:
LEIP Zoo
A broad collection of pre-trained models, for a range of applications from audio to computer vision, optimized using the LEIP SDK. Documentation and models are available to learn more about how the LEIP SDK optimizes neural networks for size and performance to handle inference workloads on edge devices.
LEIP Compress
A state-of-the-art quantization optimizer for compressing neural networks, i.e. Post Training Quantization (PTQ) and Quantization Aware Training (QAT). From your pre-trained model, LEIP Compress can quantize the neural network weights and convert all computation into lower bit-precision. The optimized model can be stored as floating point or integer representations.
LEIP Compile
An automated compiler that can generate a Latent AI Runtime Environment (LRE) object containing executable code native to the target hardware processor. The LEIP Compile module is highly flexible and can generate different variants of the LRE object. Each variant comes with different level of optimization complexity to offer range of compute and memory efficiencies.
Objectives
The Latent AI Model Zoo provides examples for developers to use LEIP Compress and LEIP Compile modules. The LEIP Zoo models and results are presented to showcase the LEIP SDK’s end-to-end workflow. We provide a small set of results for the different ways a developer can use the LEIP SDK.
For a selected set of models, we provide results for various datasets to highlight LEIP’s workflow within the ML framework (e.g. Tensorflow). We showhow LEIP SDK supports:
- Pretrained Models -- Compress and Compile models pretrained with ImageNet dataset
- Transfer Learning – Starting with a baseline pretrained ImageNet model, train the last few layers for an Open_Images_10 dataset, and then utilize Compress/Compile modules.
We also provide additional models for a variety of applications including audio recognition, and we provide examples using our Quantization Aware Training in LEIP Compress.
For evaluation, we show a comparison between the original and quantized model:
- Baseline – The original design evaluated in 32-bit floating point (FP32).
- Quantized – LEIP Compress and Compile LRE executable weights and activations in 8-bit integer.
For more information about the availability of the LEIP SDK, please feel free to contact us at info@latentai.com. You can find out more about Latent AI at our website.